 January 13, 2025
January 13, 2025How Geocodio keeps 300M addresses up to date
Working with address data requires continual updates. Our in-house ETL, built on Laravel and SQLite, helps us expand our address point data on a daily basis.
Addresses aren't static. New developments may necessitate new streets or splitting parcels, resulting in new house numbers or a streets getting a new name. So how do we keep all of our address data up-to-date?
It starts with almost 3,000 distinct data sources and an in-house data pipeline.
Chop Chop
We lovingly call our data pipeline "Chop Chop" (with a cute little crab as the mascot).
Chop Chop keeps track of data sources and allow us to go from raw data, to cleaned, normalized and validated records.
The entire platform is built on Laravel and uses Laravel Nova. We also make heavy use of queueing using Laravel Horizon.
Queueing allows us to process hundreds of sources in parallel, horizontally scaling across multiple (beefy!) dedicated servers.
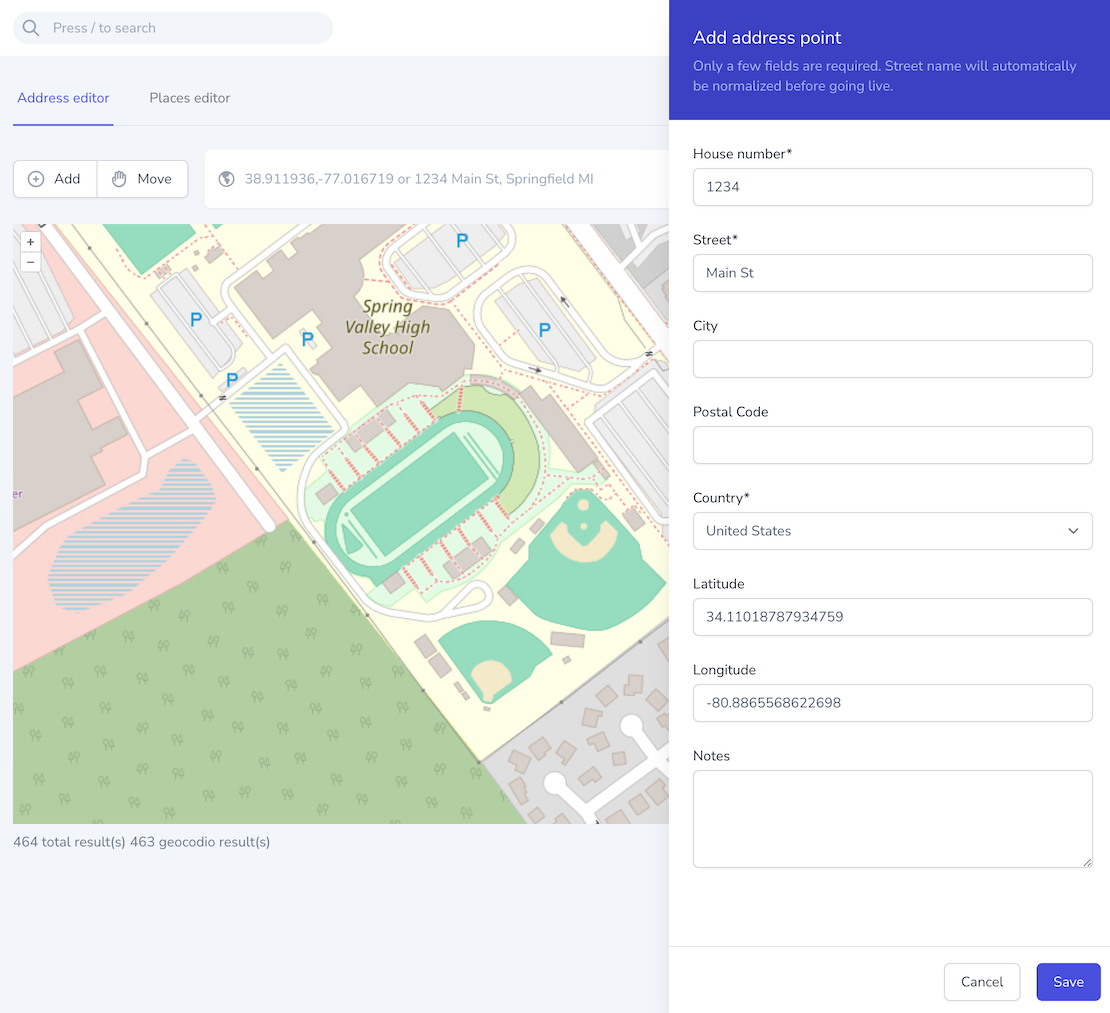
Chop Chop also includes a visual editor that allows us to perform manual data corrections as needed. In addition to the editor, we also have a powerful ability to to apply corrections in bulk using custom SQL queries.
Processing data sources
A data source is often a local county or city, and for most of these sources Chop Chop will fetch raw data directly from the source on a weekly basis. We call this a "Source Run."
The raw data is only the first step in the process. There are tons of different geographic data formats, so after we retrieve the raw data, the first step is to convert it to a common format. We use newline-delimited GeoJSON, which is a fairly efficient format that can easily be inspected by a human, diffed, and more.
The next step in the process is to enrich each record with additional data. This includes adding missing city information, missing postal codes, parsing secondary address information, and more. This also includes normalizing existing data, such as the house number and street name.
Next, it's time to validate each record and filter those out that don't meet our high quality standards. We validate things like invalid or missing house numbers, coordinates that appear to be placed incorrectly or far from where they were expected to be, and many other criteria.
For some sources, this means that we drop as much as 20-30% of the records. But this is a necessity to ensure that the geographic data we use is valid and complete.
Finally, the entire Source Run is analyzed and validated. If there are significant changes since the previous run, it is flagged for human review. If not, it is promoted so it is ready to be included with our next data release.
To encapsulate of all of this, we're using Laravel's excellent Pipeline pattern. Here's an example of what that looks like for us:
$pipes = collect([
$this->determineBuilder(),
FilterAndDecorateRecords::class,
TransformToSQL::class,
AnalyzeChanges::class,
MoveCurrentRunPointer::class,
])->flatten();
$pipes = $this->removeAlreadyProcessedStages($pipes, $this->run->stages);
app(Pipeline::class)
->send($this->run)
->through($pipes->toArray())
->thenReturn();
Putting it all together
Every night, Chop Chop pulls together the most recently validated run for each source and builds an aggregated SQLite database.
A CI job is then queued up to run our entire geocoding engine test suite with the new database build. We have a pretty substantial test suite in place which ensures that we can make frequent deployments with confidence.
A pull request is opened for a human to review the changes and approve before we can start a deployment.
Deploying data updates
Our infrastructure consists of hundreds of servers that each need a copy of this database. Since we deploy updates almost every single day, we speed up the process by pre-staging a copy of the aggregated database as soon as it has been built across our entire infrastructure.
This significantly speeds up the deployment process, as using the new database is as simple as a code change that points to the new database version instead of the previously used version.
Looking ahead
Managing hundreds of millions of addresses is no small feat, but our data pipeline makes it manageable and reliable.
The combination of automated processing and human oversight helps us maintain accurate and up-to-date address data. Whether it's a new housing development in a growing suburb or a street name change in a major city, our system catches these changes and incorporates them into our database, usually within days of the source data being updated.
As cities continue to grow and change, having reliable address data becomes increasingly critical for businesses and organizations.
Our investment in building and maintaining Chop Chop reflects our commitment to providing the most current and accurate geocoding data possible. By automating the complex tasks while maintaining human oversight for quality control, we're able to scale our operations while ensuring the high level of accuracy.